

As explained in the presentation article, Stambia can work with Google BigQuery powered by Google Cloud Platform (GCP) to perform operations on its tables, load data, reverse Metadata, ...
This article demonstrates how to work with Google BigQuery in Stambia.
Prerequisites:You must have previously installed Google Cloud Platform connector to be able to work with Google BigQuery.
Please refer to the following article that will guide you to accomplish this.
Metadata
When Stambia DI Google Cloud Platform Connector is installed and configured, you can start creating your first Metadata.
This will then allow to perform the first reverses of Metadata and first Mapping Examples.
Metadata creation
Create the Metadata, as usual, by selecting the technology in the Metadata Creation Wizard:
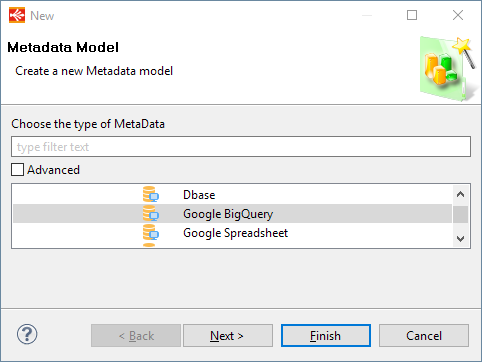
Click next, choose a name and click on finish.
Metadata Configuration
When the Metadata is created, close the connection wizard that appears automatically (we'll come back on it later.).
Before connecting, there are two specific Google BigQuery properties to define:
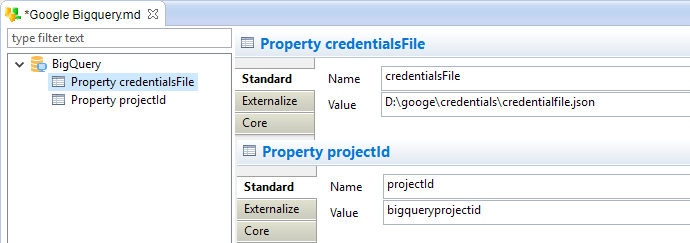
To add a property, simply right click on the root node and choose "New > Property"
The following properties need to be added:
| Property Name | Description | Example |
| credentialsFile |
Path to the Google credential file that will be used to connect to Google BigQuery. This file is most commonly a JSON file that can be retrieved from the Google Cloud Console, through the "APIs & Services / Credentials / Service account keys" menu. The service account from which the credentials is issued must have the permission to perform BigQuery operations on the Google Project specified by the "ProjectId" Property. Optionally, having also permission on Google Storage can be interesting for performance improvements.
|
D:\googe\credentials\credentialfile.json |
| projectId | The Google Project ID in which to perform BigQuery operations | bigqueryprojectid |
Connection and Reverse
The two properties being configured, you can now try connecting and reversing BigQuery datasets and tables.
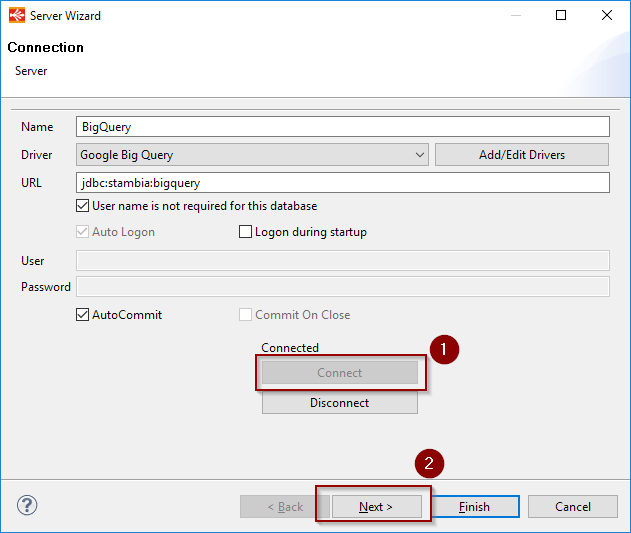
Right click on the root node and choose "Actions > Launch Wizard".
There is nothing else to configure, click on connect, and next to continue to dataset selection.
On the next window, click on refresh on the Catalog Name, then select the Google Project from the list.
Click on refresh on the Schema Name and select the Google BigQuery dataset to reverse from the list.
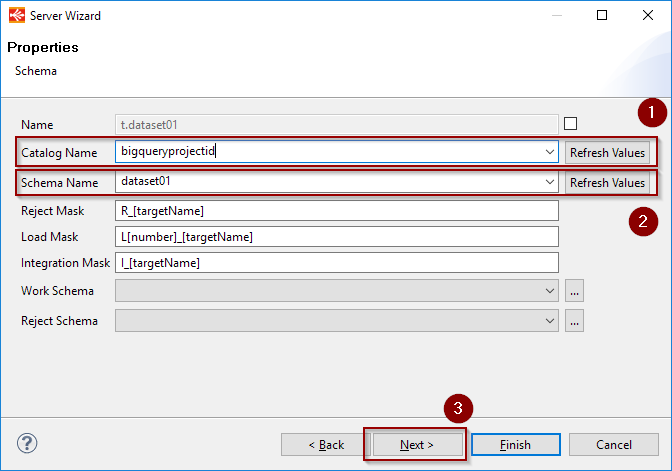
Finally click next, refresh the list of tables, and choose the ones to reverse.
After having clicked on finish the tables will be reversed in the Metadata:
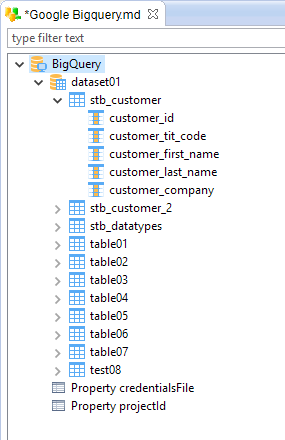
You can now start using them in your Mappings and Processes.
A few examples can be found in the next section, and a Demonstration Project is available for more complete examples.
Examples
Below are some examples of usages in Mappings in Processes:
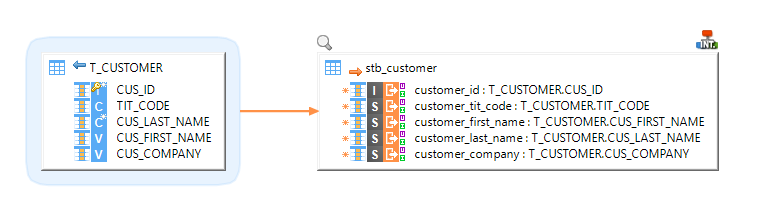
Example of Mapping loading data from an HSQL database to a Google BigQuery table
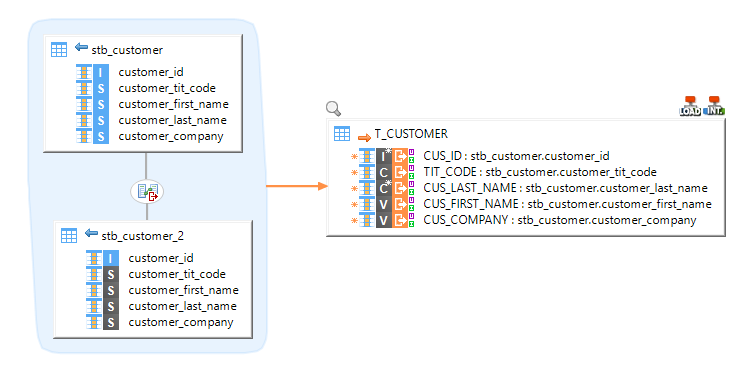
Example of Mapping loading data from multiple BigQuery tables with joins to an HSQL table
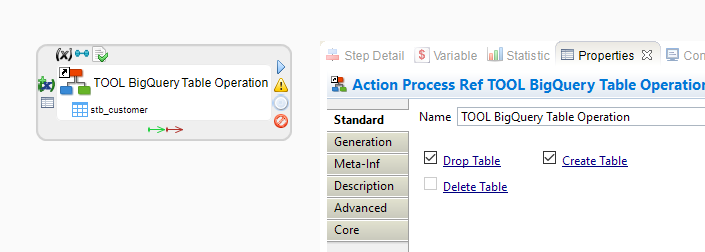
Example of a Process dropping and re-creating a BigQuery table
Demonstration Project
A demonstration project presenting common and advanced usage of the Google BigQuery Connector in Stambia can be found on the download page.
You can download and import it in your workspace and then have a look at the Mappings and Processes examples.
It is a good start to familiarize with its usage and to see how the Metadata are configured, for instance.